Technical Reflection
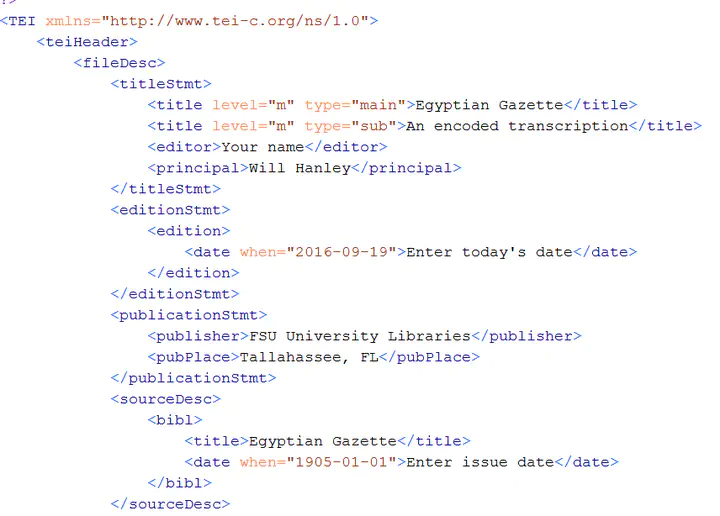
I suppose I’ll start off with how much I’ve learned so far through this course; taking digital images of film, running text recognition software, writing in Markdown and encoding in XML. Though it has all been incredibly interesting and fulfilling, the mention of those words along with “Digital Egyptian Gazette”, will likely send chills down my spine for quite a while.
To start, my largest technical obstacle was the poor job done by Fine Reader. While it truly saved me a lot of time by translating the text, it also made an overwhelming amount of errors that are incredibly time-consuming and painstaking to correct. If I were to make an estimate, correcting and encoding one page of the newspaper takes about three and a half hours. Aside from that I have had trouble with putting together the tables and advertisements in my week. Several of them do not yet exist as text files that I can pull from and for the ones that I do have access to, it takes about three copy and pastes before I trigger an “abuse mechanism” on GitHub. This locks me out for a couple of minutes before I can get back to work. But regardless, we push onward!
Jacob Stefonek
Student
The author, a student at Florida State University, was enrolled in the digital microhistory lab in fall 2016.