Querying the Digital Egyptian Gazette
Objective
We are digitizing the Egyptian Gazette to make its contents searchable. Plain text can be searched with keywords, but TEI-XML encoded text can be searched in more precise ways. For example, if you search for “London” in plain text, you would find hundreds and hundreds of repeated references to London in ads and tables. TEI-XML allows you to search for “London” in specific parts of the newspaper: page 3, for example, or local news. Restricting your search to these locations can give you more useful results.
The two main query (search) languages for XML are XPath and XQuery. This tutorial focuses on XPath as used in the Oxygen XML editor. An XPath is a series of terms (words) separated by slashes (/) and other punctuation that describes a specific location or locations in an XML file. For example, the XPath //div[@type="section"]/div/p[contains(., 'cotton')] describes paragraphs containing the word “cotton” that are contained in any div that is itself contained in a div that is defined as a section. This tutorial explains how to use this powerful tool.
1. Setting up queries in the Oxygen XML editor
Oxygen XML Editor allows you to run queries in several different ways. For our purposes, the most useful are a) Find and Replace and b) the XPath query bar
A) Find and Replace
If you are searching for a specific word or phrase, or searching using regular expressions, it’s easiest to use Find and Replace. You can search for the word everywhere in a file, or in specific parts of that file, by restricting the search to a certain XPath.
Searching a single file
Open the file that you wish to search in the Oxygen XML editor. Then, click on Find/Replace (the magnifying glass). This will allow you to search for a keyword in the open file. The results will be displayed at the bottom of the editor. Click on any item in this list to be taken to that location in your file.
As an example, search for Egypt. Then, search for Egypt, but restrict your XPath to div[@type="page"][@n="3"], which will restrict your search to page 3 only. Copmpare the results of these two searches.
Searching several files
Open all of the files that you wish to search, then click on Find/Replace in Files:
Searching the full contents of the digital Egyptian Gazette
To search everything in the Digital Egyptian Gazette content repository, under Find/Replace in Files > Scope, choose “Specified path,” then navigate to the location where you’ve cloned your fork of the content repository. For more information about how to find this location, consult the Github tutorial.
B) XPath query bar
If you are searching for particular nodes rather than words, or counting nodes, it’s easiest to use the XPath query bar, which is located near the top left of your screen.

The drop-down icon on the left of this box allows you to choose the scope of your search: current file, all opened files, and other options. To search the full contents of the digital Egyptian Gazette, you’ll need to use a “working set.”
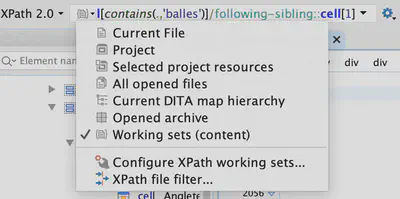
Set up a working set
To create a working set of files for your search, click on “Configure XPath working sets…” in the drop down menu pictured above. Create a “New working set”, give it a name, then press enter. Now click “Add resources,” then “Folders,” then select the content folder you’ve cloned from GitHub. Click “Done” and “Ok”, and you should be ready to query the full contents.
Basic XPath queries
Set the scope to “Current File,” then try these basic queries:
//divreturns a list of all the “divs” in your file//div[@type="item"]returns a list of all the item-type divs in your file//div[@type="item"][contains(., 'cotton')]returns a list of all the item-type divs in your file containing the word “cotton”
2. The What and Where of XPath
Once you have the basic parameters set up, it’s time to look a bit more carefully at the logic of XPath. XPath asks you to do two things: specify where you want to search, and specify what you want to search for.
“Where” searches
We use XML to structure our issues of the Egyptian Gazette by page, section, item, and so on. For example, we use nesting pairs of tags to put <div type="item"> </div> inside <div type="section"> </div>, and <div type="section"> </div> inside <div type="page"> </div>.
This structure is commonly described as a “tree.” The root is the issue, which branches into six or eight pages, and each page branches into sections and items and paragraphs.
An XPath query shows the tree parts separated by slashes, starting from root and heading towards the branches, like so:
//div[@type="page"]/div[@type="section"]/div[@type="item"]/p
A double slash (//) tells the computer to look anywhere in the document for the item that comes next. A single slash (/) tells the computer to look only one level up the tree. What difference does this make?
//div//headwould return any headline in any div in the whole document. This would not be a very good search, because it would return a huge number of results.//div/div/div/div/headwould return any paragraph that is inside four divisions (for instance, a paragraph in an item in a section in a page). This would return fewer results.
The best way to say exactly where you want to look is by using attributes. These are contained in square brackets. For example, if you want to search for the headlines within page 1 only, you would say //div[@type="page"][@n="1"]//head. What goes in the square brackets is the attributes you put in the <div> tag when you’re encoding the issues.
With a little practice, you’ll learn to search for results only in the relevant parts of the newspaper.
“What” searches
After you tell XPath where you want it to search, you can tell it what you want it to return. (This is optional.) Probably the most common thing to search for is a word or words. To do this, add [contains(., "searchtext")] to the end of your search, putting your search word(s) between the quotation marks. For example, //div[contains(., "plague")] will return all divs that contain the word “plague.” Note that this search is case sensitive, and will not return “PLAGUE” and “Plague.” To remedy this ,use the matches function with the 'i' flag, which makes the search case insensitive: //div[matches(.,'the plague', 'i')].
You can also search for particular kinds of information. Add a slash to the end of the location, then tell it you want
count()– how many of these things are there?string()– what is the string of text this thing contains?number()– what number is found on this branch?
3. Navigating the tree
You can navigate around the tree by using commands like parent:: or following-sibling:: instead of the slash. These will move you up and down the tree.
For example:
- Return all datelines contained in a “cable” div type:
//div[@type="cable"]/parent::div//dateline - Return all placeNames in cable:
//div[@type="cable"]/parent::div//dateline//placeName
Search using xml:id or feature
Many ads, templates, and sections have xml:id or feature tags embedded in them. These are meant to simplify your search. For features, use //div[@feature="shippingMovements"]. For tables, use //table[@xml:id="deg-ta-cppa01"].
4. Working with tables
Tables are a powerful part of the XML-encoded Egyptian Gazette. XPath gives us tools to return precise parts of the information these tables contain. For example:
- return the text contained in the cell after a cell containing the text “P.T.”
//table//cell[contains(.,'P.T.')]/following-sibling::cell[1]/text(). Does not work for numbers, it seems. - return the number contained in the cell after a cell containing the text “Augment.”
//table//cell[contains(.,'Augment.')]/following-sibling::cell[1]/number(). Does not work if number appears as a string (i.e. contains a comma after the thousands for example). - return the string contained in the cell after a cell containing the text “Augment.”
//table//cell[contains(.,'Augment.')]/following-sibling::cell[1]/string() - return the string text of the first paragraph of the div with the heading “MARCHE DE MINET”
//div//head[contains(.,'MARCHE DE MINET')]/following-sibling::p[1]/string() - return the value of the “when” attribute of dates in the third line of the Orient-Royal Mail Line ad:
//div[@xml:id="deg-ad-orm01"]//head/following-sibling::p[3]/date/@when
An example of working your way through table cells, looking at prices for cotton:
- This query will look at all tables and return the value in the fourth cell to the right of the cell containing the word “Cotton”:
//table//cell[contains(.,'Cotton')]/following-sibling::cell[4] - This query will look at the “Coton” table (which has an xml:id of “deg-ta-cotn01”), and return the value in the cell to the right of the cell containing the word “Russie”:
//table[@xml:id="deg-ta-cotn01"]//cell[contains(.,'Russie')]/following-sibling::cell[1]
5. Recipe book
The possibilities are endless. Here are some samples.
Searching for instances of particular words
- Return all placename items that contain the word “Aden”:
//placeName[contains(.,'Aden')]
Counting instances
- Count the number of items containing the term ’native’:
count(//div[contains(., 'native')]) - count the number of ads (divs) on page 1 (div n=“1”):
count(//div[@n="1"]//div) - count the number of paragraphs in the division whose heading contains “MARCHE DE MINET”:
count(//div/head[contains(.,'MARCHE DE MINET')]/following-sibling::p)
Item length
- Find all paragraphs longer than 5000 characters:
//p[string-length() > 5000]
Exclude Section/div/Page
- Search all the divs after Page 1:
//div[not(descendant::div[@n="1"]) and not(ancestor-or-self::div[@n="1"])]
Search for one word but not another
- Search for paragraphs containing the word “theatre” but not the word “performance”:
//p[contains(.,'theatre')]/text() | //p[contains(.,'theatre')]/*[not(contains(.,'performance'))]/text()
6. Searching with regular expressions
It is possible to combine regular expression and XPath searches by using the find/replace menu. Enter the regular expression you wish to search for in the Find box, and the XPath location in which you wish to search in the XPath box. <!— explain further —>
7. Export and manipulate results
Right click on results, then export file. You can then clean up these results with regular expressions to remove the parts you don’t want. After this, you can work with the results in a spreadsheet.
8. XQuery
More complex querying can be accomplished using XQuery.
Example, returning the date of every issue with a page 7:
for $a in collection("file:/Users/whanley/GitHub/DEG-content/?select=1905-*.xml;recurse=yes") where $a//*:div[@n="7"] return $a//*:bibl/*:date
Identify six versus eight page issues:
for $a in collection("file:/Users/whanley/GitHub/DEG-content/?select=1905-*.xml;recurse=yes") return if ($a//*:div[@n="7"]) then <eight-page>{data($a//*:bibl/*:date)}</eight-page> else <six-page>{data($a//*:bibl/*:date)}</six-page>
9. Resources
- XPath functions list
- W3C XPath functions list
- XPath tutorial
- Got a question or comment? File an issue here.